
صورة من المؤلف | منشئ صور بنج
دوللي 2.0 هو نموذج لغة كبير مفتوح المصدر ، يتبع التعليمات ، تم ضبطه بدقة على مجموعة بيانات تم إنشاؤها بواسطة الإنسان. يمكن استخدامه للأغراض البحثية والتجارية.
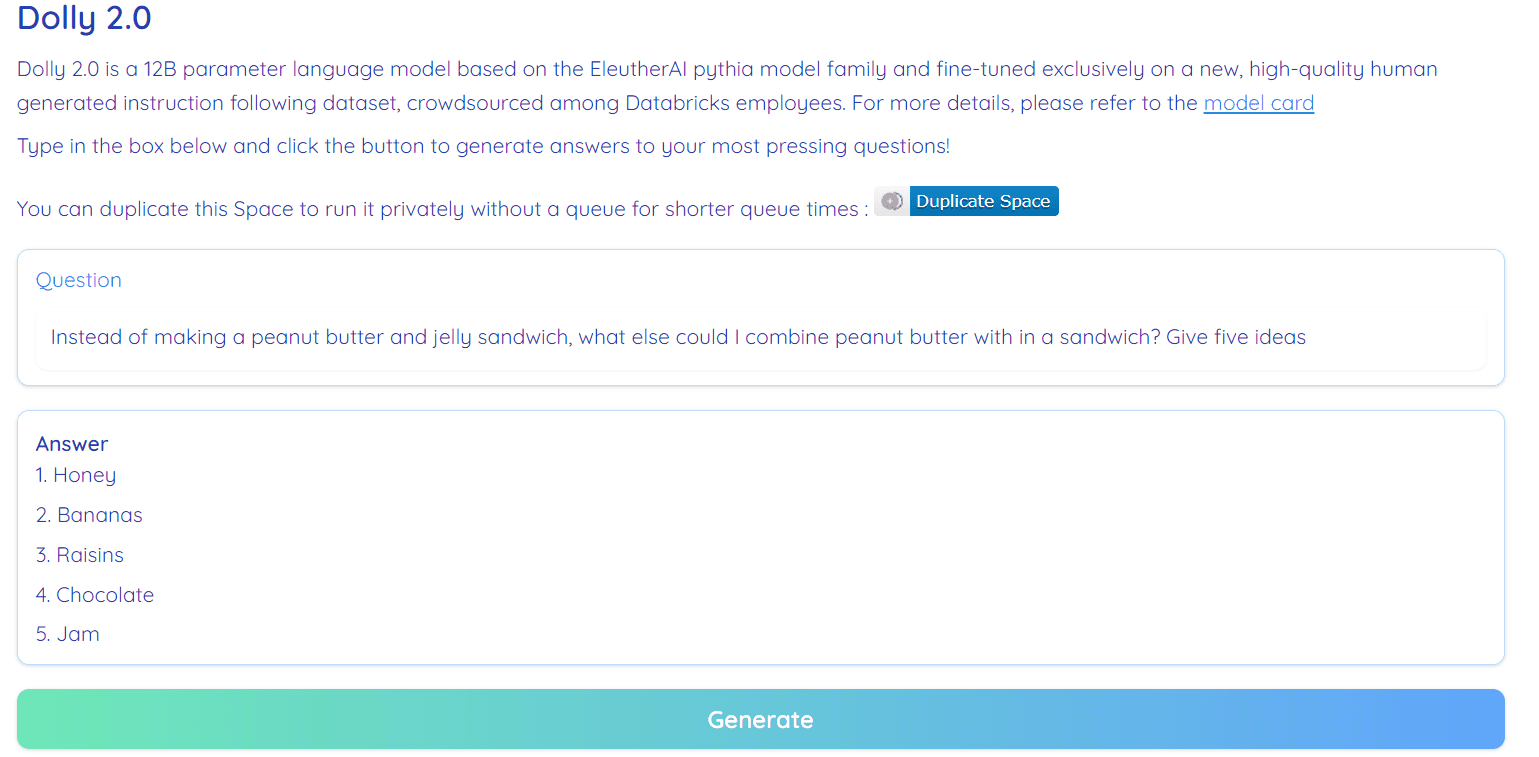
صورة من مساحة تعانق الوجه بواسطة RamAnanth1
في السابق ، أطلق فريق Databricks دوللي 1.0، LLM ، التي تعرض تعليمات تشبه ChatGPT بعد القدرة وتكلفة التدريب أقل من 30 دولارًا. كانت تستخدم مجموعة بيانات فريق Stanford Alpaca ، والتي كانت بموجب ترخيص مقيد (للأبحاث فقط).
حل Dolly 2.0 هذه المشكلة عن طريق ضبط نموذج لغة معلمة 12B (بيثيا) على تعليمات عالية الجودة من صنع الإنسان في مجموعة البيانات التالية ، والتي تم تصنيفها بواسطة موظف Datbricks. يتوفر كل من الطراز ومجموعة البيانات للاستخدام التجاري.
تم تدريب Dolly 1.0 على مجموعة بيانات Stanford Alpaca ، والتي تم إنشاؤها باستخدام OpenAI API. تحتوي مجموعة البيانات على ناتج ChatGPT وتمنع أي شخص من استخدامه للتنافس مع OpenAI. باختصار ، لا يمكنك إنشاء روبوت محادثة تجاري أو تطبيق لغة بناءً على مجموعة البيانات هذه.
عانت معظم أحدث الموديلات التي تم إصدارها في الأسابيع القليلة الماضية من نفس المشكلات ، مثل عارضات الأزياء صوف الألبكة, الكوال دب أسترالي, GPT4 الكلو فيكونيا. للتجول ، نحتاج إلى إنشاء مجموعات بيانات جديدة عالية الجودة يمكن استخدامها للاستخدام التجاري ، وهذا ما فعله فريق Databricks مع مجموعة البيانات databricks-dolly-15k.
تحتوي مجموعة البيانات الجديدة على 15,000 زوج من الأزواج السريعة / الاستجابة عالية الجودة التي يمكن استخدامها لتصميم تعليمات لضبط نماذج اللغة الكبيرة. ال databricks-دوللي-15 كيلو تأتي مجموعة البيانات مع Creative Commons Attribution-ShareAlike 3.0 ترخيص Unportedوالذي يسمح لأي شخص باستخدامه وتعديله وإنشاء تطبيق تجاري عليه.
كيف أنشأوا مجموعة البيانات databricks-dolly-15k؟
بحث OpenAI ورقة تنص على أن نموذج InstructGPT الأصلي قد تم تدريبه على 13,000 مطالبة واستجابة. باستخدام هذه المعلومات ، بدأ فريق Databricks العمل عليها ، واتضح أن إنشاء 13 ألف سؤال وإجابات كان مهمة صعبة. لا يمكنهم استخدام البيانات التركيبية أو البيانات المولدة للذكاء الاصطناعي ، وعليهم إنشاء إجابات أصلية لكل سؤال. هذا هو المكان الذي قرروا فيه استخدام 5,000 موظف في Databricks لإنشاء بيانات من صنع الإنسان.
أقامت Databricks مسابقة ، حيث سيحصل أفضل 20 صانعًا على جائزة كبيرة. في هذه المسابقة ، شارك 5,000 موظف Databricks وكانوا مهتمين جدًا بـ LLMs
لا يعد الطراز dolly-v2-12b نموذجًا متطورًا. إنه أقل من أداء dolly-v1-6b في بعض معايير التقييم. قد يرجع ذلك إلى تكوين مجموعات البيانات الأساسية التي يتم ضبطها وحجمها. عائلة طراز Dolly قيد التطوير النشط ، لذلك قد ترى إصدارًا محدثًا بأداء أفضل في المستقبل.
باختصار ، كان أداء نموذج dolly-v2-12b أفضل من EleutherAI / gpt-neox-20b و EleutherAI / pythia-6.9b.

صورة من دوللي الحرة
Dolly 2.0 مفتوح المصدر بنسبة 100٪. يأتي مع رمز التدريب ومجموعة البيانات وأوزان النموذج وخط أنابيب الاستدلال. جميع المكونات مناسبة للاستخدام التجاري. يمكنك تجربة النموذج على Hugging Face Spaces Dolly V2 بواسطة RamAnanth1.
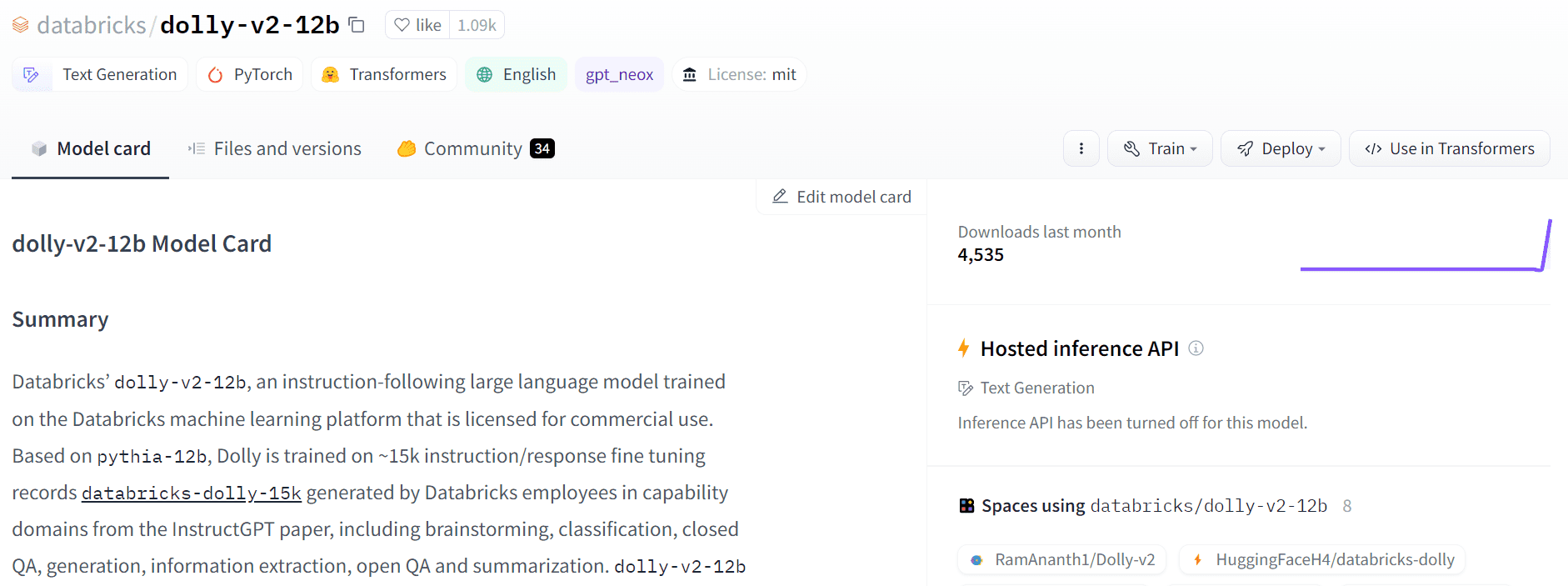
صورة من وجه يعانق
الموارد:
عرض Dolly 2.0: Dolly V2 بواسطة RamAnanth1
عابد علي عوان (@ 1abidaliawan) هو عالم بيانات متخصص محترف يحب بناء نماذج التعلم الآلي. يركز حاليًا على إنشاء المحتوى وكتابة مدونات تقنية حول تقنيات التعلم الآلي وعلوم البيانات. عابد حاصل على درجة الماجستير في إدارة التكنولوجيا ودرجة البكالوريوس في هندسة الاتصالات. تتمثل رؤيته في بناء منتج للذكاء الاصطناعي باستخدام شبكة عصبية بيانية للطلاب الذين يعانون من مرض عقلي.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- بلاتوبلوكشين. Web3 Metaverse Intelligence. تضخيم المعرفة. الوصول هنا.
- سك المستقبل مع أدرين أشلي. الوصول هنا.
- المصدر https://www.kdnuggets.com/2023/04/dolly-20-chatgpt-open-source-alternative-commercial.html?utm_source=rss&utm_medium=rss&utm_campaign=dolly-2-0-chatgpt-open-source-alternative-for-commercial-use
- :لديها
- :يكون
- :ليس
- $ UP
- 000
- 1
- 20
- a
- القدرة
- نشط
- AI
- الكل
- يسمح
- البديل
- an
- و
- الأجوبة
- أي شخص
- API
- تطبيق
- هي
- حول
- المؤلفة
- متاح
- جائزة
- على أساس
- BE
- المعايير
- بيركلي
- أفضل
- كبير
- بنج
- المدونة
- على حد سواء
- نساعدك في بناء
- ابني
- by
- CAN
- لا تستطيع
- معتمدة
- chatbot
- شات جي بي تي
- الكود
- تجاري
- جميل
- تنافس
- مكونات
- يحتوي
- محتوى
- انشاء محتوى
- مسابقة
- التكاليف
- خلق
- خلق
- خلق
- حاليا
- البيانات
- علم البيانات
- عالم البيانات
- Databricks
- قواعد البيانات
- قررت
- الدرجة العلمية
- تجربة
- تصميم
- التطوير التجاري
- فعل
- صعبة
- عربة
- موظف
- الموظفين
- الهندسة
- تقييم
- كل
- المعارض
- الوجه
- للعائلات
- قليل
- التركيز
- متابعيك
- في حالة
- تبدأ من
- مستقبل
- توليد
- توليد
- توليدي
- دولار فقط واحصل على خصم XNUMX% على جميع
- رسم بياني
- الشبكة العصبية للرسم البياني
- يملك
- he
- عالي الجودة
- يحمل
- HTML
- HTTPS
- مرض
- صورة
- in
- معلومات
- يستفد
- قضية
- مسائل
- IT
- JPG
- KD nuggets
- لغة
- كبير
- اسم العائلة
- آخر
- تعلم
- حقوق الملكية الفكرية
- مثل
- آلة
- آلة التعلم
- إدارة
- رئيسي
- عقلي
- المرض العقلي
- ربما
- نموذج
- عارضات ازياء
- تعديل
- حاجة
- شبكة
- عصبي
- الشبكة العصبية
- جديد
- of
- on
- فقط
- جاكيت
- المصدر المفتوح
- OpenAI
- or
- أصلي
- الناتج
- أزواج
- المعلمة
- شارك
- أداء
- خط أنابيب
- أفلاطون
- الذكاء افلاطون البيانات
- أفلاطون داتا
- منتج
- محترف
- أغراض
- سؤال
- الأسئلة المتكررة
- صدر
- بحث
- حل
- مقيد
- s
- نفسه
- علوم
- عالم
- طقم
- قصير
- مقاس
- So
- بعض
- مصدر
- الفضاء
- المساحات
- ستانفورد
- بدأت
- دولة من بين الفن
- المحافظة
- يكافح
- عدد الطلبة
- مناسب
- اصطناعي
- البيانات الاصطناعية
- مهمة
- فريق
- تقني
- التكنولوجيا
- تكنولوجيا
- اتصالات
- من
- أن
- •
- المستقبل
- هم
- إلى
- تيشرت
- قطار
- متدرب
- قادة الإيمان
- مع
- التي تقوم عليها
- تحديث
- تستخدم
- مستعمل
- استخدام
- الإصدار
- رؤيتنا
- وكان
- we
- أسابيع
- كان
- ابحث عن
- التي
- من الذى
- مع
- للعمل
- سوف
- جاري الكتابة
- لصحتك!
- زفيرنت










