العثور على أعمدة مماثلة في أ بحيرة البيانات لديها تطبيقات مهمة في تنظيف البيانات والتعليقات التوضيحية ومطابقة المخطط واكتشاف البيانات والتحليلات عبر مصادر بيانات متعددة. يمثل عدم القدرة على العثور على البيانات وتحليلها بدقة من مصادر مختلفة قاتلًا محتملاً للكفاءة للجميع من علماء البيانات والباحثين الطبيين والأكاديميين إلى المحللين الماليين والحكوميين.
تتضمن الحلول التقليدية البحث المعجمي بالكلمات الرئيسية أو مطابقة التعبير العادي ، والتي تكون عرضة لمشاكل جودة البيانات مثل أسماء الأعمدة الغائبة أو اصطلاحات تسمية الأعمدة المختلفة عبر مجموعات البيانات المتنوعة (على سبيل المثال ، zip_code, zcode, postalcode).
في هذا المنشور ، نعرض حلاً للبحث عن أعمدة مماثلة بناءً على اسم العمود أو محتوى العمود أو كليهما. يستخدم الحل تقريبي خوارزميات الجيران متوفر في خدمة Amazon OpenSearch للبحث عن أعمدة متشابهة لغويًا. لتسهيل البحث ، نقوم بإنشاء تمثيلات الميزات (التضمينات) للأعمدة الفردية في بحيرة البيانات باستخدام نماذج المحولات المدربة مسبقًا من مكتبة محولات الجملة in الأمازون SageMaker. أخيرًا ، للتفاعل مع النتائج وتصورها من حلنا ، نقوم ببناء تفاعل انسيابي تطبيق ويب يعمل على AWS فارجيت.
نقوم بتضمين أ تعليمي كود لك لنشر الموارد لتشغيل الحل على بيانات نموذجية أو بياناتك الخاصة.
حل نظرة عامة
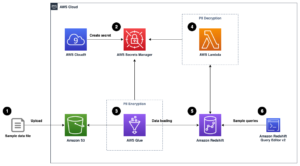
يوضح الرسم التخطيطي للهندسة المعمارية التالي سير العمل على مرحلتين للعثور على أعمدة متشابهة لغويًا. المرحلة الأولى يدير وظائف خطوة AWS سير العمل الذي يُنشئ التضمينات من الأعمدة المجدولة ويبني فهرس بحث OpenSearch Service. تقوم المرحلة الثانية ، أو مرحلة الاستدلال عبر الإنترنت ، بتشغيل تطبيق Streamlit من خلال Fargate. يقوم تطبيق الويب بجمع استعلامات بحث الإدخال واسترداد من فهرس خدمة البحث المفتوح الأعمدة التقريبية k-most-مماثلة للاستعلام.

الشكل 1. هندسة الحل
يستمر سير العمل الآلي في الخطوات التالية:
- يقوم المستخدم بتحميل مجموعات البيانات المجدولة في ملف خدمة تخزين أمازون البسيطة (Amazon S3) ، والذي يستدعي ملف AWS لامدا الوظيفة التي تبدأ سير عمل "وظائف الخطوة".
- يبدأ سير العمل بامتداد غراء AWS المهمة التي تحول ملفات CSV إلى ملفات اباتشي باركيه تنسيق البيانات.
- تُنشئ وظيفة معالجة SageMaker عمليات التضمين لكل عمود باستخدام نماذج مُدرَّبة مسبقًا أو نماذج تضمين عمود مخصصة. تحفظ مهمة معالجة SageMaker عمليات دمج الأعمدة لكل جدول في Amazon S3.
- تقوم وظيفة Lambda بإنشاء مجال OpenSearch Service والكتلة لفهرسة عمليات دمج الأعمدة التي تم إنتاجها في الخطوة السابقة.
- أخيرًا ، يتم نشر تطبيق ويب Streamlit تفاعلي مع Fargate. يوفر تطبيق الويب واجهة للمستخدم لإدخال استعلامات للبحث في مجال خدمة OpenSearch Service عن أعمدة مماثلة.
يمكنك تنزيل البرنامج التعليمي للكود من GitHub جيثب: لتجربة هذا الحل على بيانات نموذجية أو بياناتك الخاصة. تتوفر تعليمات حول كيفية نشر الموارد المطلوبة لهذا البرنامج التعليمي على جيثب.
الشروط المسبقة
لتنفيذ هذا الحل ، تحتاج إلى ما يلي:
- An حساب AWS.
- الإلمام الأساسي بخدمات AWS مثل مجموعة تطوير سحابة AWS (AWS CDK) و Lambda و OpenSearch Service و SageMaker Processing.
- مجموعة بيانات مجدولة لإنشاء فهرس البحث. يمكنك إحضار البيانات المجدولة الخاصة بك أو تنزيل نماذج مجموعات البيانات على GitHub جيثب:.
بناء فهرس بحث
تقوم المرحلة الأولى ببناء فهرس محرك بحث العمود. يوضح الشكل التالي سير عمل Step Functions الذي يعمل في هذه المرحلة.

الشكل 2 - سير عمل وظائف الخطوة - نماذج تضمين متعددة
قواعد البيانات
في هذا المنشور ، قمنا ببناء فهرس بحث ليشمل أكثر من 400 عمود من أكثر من 25 مجموعة بيانات مجدولة. تنشأ مجموعات البيانات من المصادر العامة التالية:
للحصول على القائمة الكاملة للجداول المضمنة في الفهرس ، راجع البرنامج التعليمي للرمز على GitHub جيثب:.
يمكنك إحضار مجموعة البيانات المجدولة الخاصة بك لزيادة عينة البيانات أو إنشاء فهرس البحث الخاص بك. نقوم بتضمين وظيفتين من وظائف Lambda التي تبدأ سير عمل Step Functions لإنشاء فهرس البحث لملفات CSV الفردية أو مجموعة من ملفات CSV ، على التوالي.
تحويل CSV إلى باركيه
يتم تحويل ملفات Raw CSV إلى تنسيق بيانات Parquet باستخدام AWS Glue. الباركيه هو تنسيق ملف ذو توجه عمودي مفضل في تحليلات البيانات الضخمة التي توفر ضغطًا وترميزًا فعالين. في تجاربنا ، قدم تنسيق بيانات باركيه انخفاضًا كبيرًا في حجم التخزين مقارنة بملفات CSV الأولية. استخدمنا أيضًا باركيه كتنسيق بيانات شائع لتحويل تنسيقات البيانات الأخرى (على سبيل المثال JSON و NDJSON) لأنه يدعم هياكل البيانات المتداخلة المتقدمة.
إنشاء حفلات الزفاف ذات الأعمدة المجدولة
لاستخراج حفلات الزفاف لأعمدة الجدول الفردية في نماذج مجموعات البيانات المجدولة في هذا المنشور ، نستخدم النماذج التالية المدربة مسبقًا من sentence-transformers مكتبة. للحصول على نماذج إضافية ، انظر نماذج محددة مسبقا.
تعمل وظيفة معالجة SageMaker create_embeddings.py(الكود) لطراز واحد. لاستخراج الزخارف من نماذج متعددة ، يقوم سير العمل بتشغيل مهام SageMaker Processing المتوازية كما هو موضح في سير عمل Step Functions. نستخدم النموذج لإنشاء مجموعتين من الزخارف:
- العمود_اسم_الأفراح - ترسيخ أسماء الأعمدة (رؤوس)
- عمود_محتوى_حفلات الزفاف - متوسط التضمين لجميع الصفوف في العمود
لمزيد من المعلومات حول عملية تضمين العمود ، راجع البرنامج التعليمي للتعليمات البرمجية على GitHub جيثب:.
يتمثل أحد البدائل لخطوة معالجة SageMaker في إنشاء تحويل دفعة SageMaker للحصول على زخارف أعمدة على مجموعات البيانات الكبيرة. قد يتطلب ذلك نشر النموذج إلى نقطة نهاية SageMaker. لمزيد من المعلومات، راجع استخدم تحويل الدُفعات.
فهرس حفلات الزفاف مع خدمة البحث المفتوح
في الخطوة الأخيرة من هذه المرحلة ، تضيف وظيفة Lambda تضمين الأعمدة إلى خدمة OpenSearch Service التقريبية لـ k-Nearest-Neighbor (kNN) فهرس البحث. يتم تعيين فهرس البحث الخاص به لكل نموذج. لمزيد من المعلومات حول معلمات فهرس بحث kNN التقريبية ، راجع ك- NN.
الاستدلال عبر الإنترنت والبحث الدلالي باستخدام تطبيق ويب
يتم تشغيل المرحلة الثانية من سير العمل انسيابي تطبيق ويب حيث يمكنك تقديم مدخلات والبحث عن أعمدة متشابهة لغويًا مفهرسة في خدمة OpenSearch Service. تستخدم طبقة التطبيق ملف موازن تحميل التطبيقوفارجيت ولامدا. يتم نشر البنية الأساسية للتطبيق تلقائيًا كجزء من الحل.
يتيح لك التطبيق توفير إدخال والبحث عن أسماء الأعمدة المتشابهة لغويًا أو محتوى العمود أو كليهما. بالإضافة إلى ذلك ، يمكنك تحديد نموذج التضمين وعدد أقرب الجيران للعودة من البحث. يتلقى التطبيق المدخلات ، ويقوم بتضمين المدخلات مع النموذج المحدد ، ويستخدم بحث kNN في خدمة البحث المفتوح للبحث في تضمين الأعمدة المفهرسة والعثور على الأعمدة الأكثر تشابهًا مع الإدخال المحدد. تتضمن نتائج البحث المعروضة أسماء الجداول وأسماء الأعمدة ودرجات التشابه للأعمدة المحددة ، بالإضافة إلى مواقع البيانات في Amazon S3 لمزيد من الاستكشاف.
يوضح الشكل التالي مثالاً لتطبيق الويب. في هذا المثال ، بحثنا عن أعمدة متشابهة في بحيرة البيانات الخاصة بنا Column Names (نوع الحمولة) إلى district (الحمولة). التطبيق المستخدم all-MiniLM-L6-v2 كما نموذج التضمين و عاد 10 (k) أقرب جيران من فهرس خدمة البحث المفتوح.
عاد التطبيق transit_district, city, boroughو location مثل الأعمدة الأربعة الأكثر تشابهًا استنادًا إلى البيانات المفهرسة في خدمة البحث المفتوح. يوضح هذا المثال قدرة نهج البحث على تحديد الأعمدة المتشابهة لغويًا عبر مجموعات البيانات.

الشكل 3: واجهة مستخدم تطبيق الويب
تنظيف
لحذف الموارد التي أنشأها AWS CDK في هذا البرنامج التعليمي ، قم بتشغيل الأمر التالي:
cdk destroy --allوفي الختام
في هذا المنشور ، قدمنا سير عمل شامل لبناء محرك بحث دلالي للأعمدة المجدولة.
ابدأ اليوم باستخدام بياناتك الخاصة من خلال البرنامج التعليمي الخاص بالرمز المتاح على GitHub جيثب:. إذا كنت ترغب في المساعدة في تسريع استخدامك لـ ML في منتجاتك وعملياتك ، فيرجى الاتصال بـ مختبر أمازون لحلول التعلم الآلي.
حول المؤلف
![]() كاشي أودومين هو عالم تطبيقي في AWS AI. قام ببناء حلول AI / ML لحل مشاكل الأعمال لعملاء AWS.
كاشي أودومين هو عالم تطبيقي في AWS AI. قام ببناء حلول AI / ML لحل مشاكل الأعمال لعملاء AWS.
![]() تايلور مكنالي هو مهندس تعليم عميق في مختبر حلول التعلم الآلي في أمازون. يساعد العملاء من مختلف الصناعات على بناء حلول تستفيد من الذكاء الاصطناعي / التعلم الآلي على AWS. إنه يستمتع بفنجان جيد من القهوة ، في الهواء الطلق ، والوقت مع أسرته وكلبه النشط.
تايلور مكنالي هو مهندس تعليم عميق في مختبر حلول التعلم الآلي في أمازون. يساعد العملاء من مختلف الصناعات على بناء حلول تستفيد من الذكاء الاصطناعي / التعلم الآلي على AWS. إنه يستمتع بفنجان جيد من القهوة ، في الهواء الطلق ، والوقت مع أسرته وكلبه النشط.
![]() أوستن ويلش هو عالم بيانات في Amazon ML Solutions Lab. يطور نماذج التعلم العميق المخصصة لمساعدة عملاء القطاع العام في AWS على تسريع تبني الذكاء الاصطناعي والسحابة. في أوقات فراغه ، يستمتع بالقراءة والسفر والجوجيتسو.
أوستن ويلش هو عالم بيانات في Amazon ML Solutions Lab. يطور نماذج التعلم العميق المخصصة لمساعدة عملاء القطاع العام في AWS على تسريع تبني الذكاء الاصطناعي والسحابة. في أوقات فراغه ، يستمتع بالقراءة والسفر والجوجيتسو.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- بلاتوبلوكشين. Web3 Metaverse Intelligence. تضخيم المعرفة. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/
- 1
- 100
- a
- القدرة
- من نحن
- غائب
- تسريع
- تسريع
- بدقة
- في
- إضافي
- وبالإضافة إلى ذلك
- يضيف
- تبني
- متقدم
- AI
- AI / ML
- الكل
- يسمح
- البديل
- أمازون
- آلة التعلم الأمازون
- مختبر أمازون ML Solutions
- المحللين
- تحليلات
- تحليل
- و
- أباتشي
- تطبيق
- التطبيقات
- تطبيقي
- نهج
- هندسة معمارية
- تعيين
- الآلي
- تلقائيا
- متاح
- المتوسط
- AWS
- غراء AWS
- على أساس
- لان
- كبير
- البيانات الكبيرة
- جلب
- نساعدك في بناء
- ابني
- يبني
- الأعمال
- سوائل التنظيف
- سحابة
- اعتماد السحابة
- كتلة
- الكود
- قهوة
- يجمع
- عمود
- الأعمدة
- مشترك
- مقارنة
- التواصل
- محتوى
- الاتفاقيات
- تحول
- تحويلها
- خلق
- خلق
- يخلق
- كوب
- على
- العملاء
- البيانات
- تحليلات البيانات
- بحيرة البيانات
- جودة البيانات
- عالم البيانات
- قواعد البيانات
- عميق
- التعلم العميق
- شرح
- يوضح
- نشر
- نشر
- نشر
- هدم
- التطوير التجاري
- يطور
- مختلف
- اكتشاف
- حماقة
- عدة
- كلب
- نطاق
- بإمكانك تحميله
- كل
- كفاءة
- فعال
- النهائي إلى نهاية
- نقطة النهاية
- محرك
- الأثير (ETH)
- كل شخص
- مثال
- استكشاف
- استخراج
- تسهيل
- معرفة
- للعائلات
- المميزات
- الشكل
- قم بتقديم
- ملفات
- نهائي
- أخيرا
- مالي
- العثور على
- الاسم الأول
- متابعيك
- شكل
- تبدأ من
- بالإضافة إلى
- وظيفة
- وظائف
- إضافي
- دولار فقط واحصل على خصم XNUMX% على جميع
- معطى
- خير
- حكومة
- رؤوس
- مساعدة
- يساعد
- كيفية
- كيفية
- HTML
- HTTPS
- محدد
- تحديد
- تنفيذ
- أهمية
- in
- عجز
- تتضمن
- شامل
- مؤشر
- فرد
- الصناعات
- معلومات
- البنية التحتية
- بدء
- يبادر
- إدخال
- تعليمات
- تفاعل
- التفاعلية
- السطح البيني
- يتضرع
- تنطوي
- مسائل
- IT
- وظيفة
- المشــاريــع
- جسون
- مختبر
- بحيرة
- كبير
- طبقة
- تعلم
- الاستفادة من
- المكتبة
- قائمة
- تحميل
- المواقع
- آلة
- آلة التعلم
- مطابقة
- طبي
- ML
- نموذج
- عارضات ازياء
- الأكثر من ذلك
- أكثر
- متعدد
- الاسم
- أسماء
- تسمية
- حاجة
- الجيران
- عدد
- عرضت
- online
- أخرى
- في الهواء الطلق
- الخاصة
- موازية
- المعلمات
- جزء
- أفلاطون
- الذكاء افلاطون البيانات
- أفلاطون داتا
- من فضلك
- منشور
- محتمل
- المفضل
- قدم
- سابق
- مشاكل
- العائدات
- عملية المعالجة
- العمليات
- معالجة
- أنتج
- المنتجات
- تزود
- ويوفر
- جمهور
- جودة
- الخام
- نادي القراءة
- يتلقى
- منتظم
- يمثل
- تطلب
- مطلوب
- الباحثين
- الموارد
- على التوالي
- النتائج
- عائد أعلى
- يجري
- تشغيل
- sagemaker
- عالم
- العلماء
- بحث
- محرك البحث
- البحث
- الثاني
- القطاع
- الخدمة
- خدماتنا
- باكجات
- أظهرت
- يظهر
- هام
- مماثل
- الاشارات
- عزباء
- المقاس
- حل
- الحلول
- حل
- مصادر
- محدد
- المسرح
- بدأت
- خطوة
- خطوات
- تخزين
- هذه
- الدعم
- عرضة
- جدول
- •
- من مشاركة
- عبر
- الوقت
- إلى
- اليوم
- تحول
- محولات
- السفر
- البرنامج التعليمي
- تستخدم
- مستخدم
- واجهة المستخدم
- مختلف
- الويب
- تطبيق ويب
- التي
- سير العمل
- سوف
- حل متجر العقارات الشامل الخاص بك في جورجيا
- زفيرنت