- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://www.nanowerk.com/news2/robotics/newsid=63842.php
- :يكون
- 10
- 100
- 15%
- 2023
- 7
- a
- ماهرون
- في
- اعتماد
- AI
- سواء
- الكل
- بالرغم ان
- من بين
- an
- و
- الأجوبة
- تطبيقي
- هي
- AS
- يسأل
- الجوانب
- مساعدين
- أسوشيتد
- At
- مهاجمة
- الهجمات
- متاح
- بعيدا
- BE
- يجري
- ما بين
- المليارات
- نساعدك في بناء
- الأعمال
- لكن
- by
- CAN
- بعناية
- الرئيس التنفيذي
- chatbots
- شات جي بي تي
- واضح
- صندوق توظيف برأس مال محدود
- مشترك
- الشركات
- الكمبيوتر
- قلق
- حول
- مؤتمر
- استطاع
- خلق
- خلق
- حرج
- حاليا
- الانترنت
- التاريخ
- شرح
- تظاهر
- نشر
- مفصلة
- كشف
- تطوير
- مختلف
- رقمي
- اكتشف
- dr
- الشركات
- كامل
- حتى
- دليل
- يوجد
- القائمة
- استغلال
- استخلاص
- جدا
- ساحر
- مالي
- الخدمات المالية
- الاسم الأول
- ركز
- في حالة
- تبدأ من
- إضافي
- اكتسبت
- معطى
- إعطاء
- أرض
- يملك
- مخفي
- ويبرز
- استضافت
- كيفية
- كيفية
- لكن
- HTTPS
- تعانق الوجه
- أهمية
- in
- زيادة
- على نحو متزايد
- العالمية
- إعلام
- معلومات
- امن المعلومات
- الثاقبة
- Internet
- استثمر
- الاستثمار
- IT
- JPG
- القفل
- المعرفة
- معروف
- لغة
- كبير
- الشركات الكبيرة
- إطلاق
- قيادة
- تعلم
- تعلم
- أقل
- القليل
- آلة
- آلة التعلم
- رائد
- مايو..
- قياس
- ملايين
- نموذج
- عارضات ازياء
- كثيرا
- جديد
- of
- on
- جاكيت
- المصدر المفتوح
- or
- خارج
- الخاصة
- ورق
- حفلة
- بيتر
- وجهات
- تخطيط
- أفلاطون
- الذكاء افلاطون البيانات
- أفلاطون داتا
- ممكن
- يحتمل
- قوي
- إعداد
- قدم
- رئيسي
- خاص
- تزود
- علانية
- نطاق
- معدل
- منسوخة
- طلبات
- بحث
- الباحثين
- كشف
- المخاطر
- قال
- قول
- العلماء
- أمن
- خدماتنا
- طقم
- ينبغي
- إظهار
- الأصغر
- سمارت
- So
- بعض
- مصدر
- المسرح
- بدء
- عاصفة
- دراسة
- تحقيق النجاح
- بنجاح
- هذه
- اتخذت
- الحديث
- المستهدفة
- استهداف
- المهام
- فريق
- التكنولوجيا
- تكنولوجيا
- الاختبار
- من
- أن
- •
- المعلومات
- المملكة المتحدة
- العالم
- من مشاركة
- then
- هناك.
- تشبه
- هم
- اعتقد
- الثالث
- هذا العام
- مرات
- إلى
- أدوات
- نقل
- التحويلية
- Uk
- فهم
- تعهد
- جامعة
- تستخدم
- مستعمل
- يستخدم
- قيمتها
- جدا
- نقاط الضعف
- وكان
- طريق..
- we
- أسبوع
- كان
- التي
- واسع
- مدى واسع
- سوف
- مع
- في غضون
- بدون
- للعمل
- اكتشف - حل
- أعمال
- العالم
- مقلق
- عام
- زفيرنت
اكثر من نانوويرك
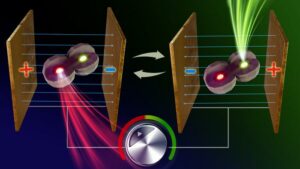
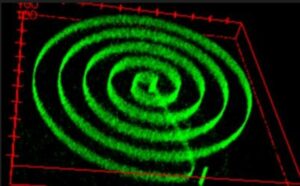
إطلاق العنان لعصر جديد من أجهزة النانو القابلة للضبط بالألوان - أصغر مصدر للضوء على الإطلاق مع تشكيل ألوان قابلة للتبديل
عقدة المصدر: 2801585
الطابع الزمني: أغسطس 3، 2023

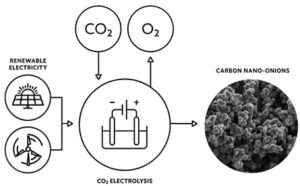
قد تلعب أنابيب الكربون النانوية دورًا مهمًا في ربط ثاني أكسيد الكربون في الغلاف الجوي
عقدة المصدر: 2836729
الطابع الزمني: أغسطس 21، 2023

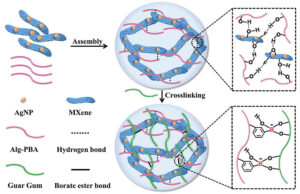
مستشعرات البشرة المضادة للبكتيريا القائمة على هيدروجيل MXene
عقدة المصدر: 2661017
الطابع الزمني: 18 مايو 2023
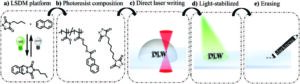
تنضم المطبوعات ثلاثية الأبعاد إلى الجانب المظلم وتختفي
عقدة المصدر: 2903619
الطابع الزمني: سبتمبر 27، 2023
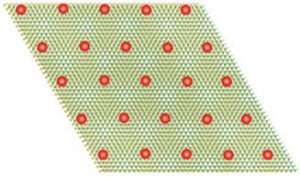
عندما تصبح المادة كمومية ، تتباطأ الإلكترونات وتشكل بلورة
عقدة المصدر: 1975767
الطابع الزمني: فبراير 23، 2023

يطور المهندسون عملية فعالة لإنتاج الوقود من ثاني أكسيد الكربون
عقدة المصدر: 2963812
الطابع الزمني: أكتوبر 30، 2023