15 مقتطفات من Python لتحسين خط أنابيب علوم البيانات
حلول Python السريعة لمساعدة دورة علوم البيانات الخاصة بك.
By لوكاس سواريس، Machine Learning Engineer في K1 Digital

تصوير كارلوس موزا on Unsplash
لماذا المقتطفات مهمة لعلوم البيانات
في روتيني اليومي ، يجب أن أتعامل مع الكثير من المواقف نفسها من تحميل ملفات csv إلى تصور البيانات. لذلك ، للمساعدة في تبسيط عمليتي ، قمت بإنشاء عادة تخزين مقتطفات من التعليمات البرمجية التي تكون مفيدة في مواقف مختلفة من تحميل ملفات csv إلى تصور البيانات.
في هذا المنشور ، سأشارك 15 مقتطفًا من التعليمات البرمجية للمساعدة في الجوانب المختلفة لخط أنابيب تحليل البيانات الخاص بك
1. تحميل ملفات متعددة باستخدام glob و list comprehension
import glob
import pandas as pd
csv_files = glob.glob("path/to/folder/with/csvs/*.csv")
dfs = [pd.read_csv(filename) for filename in csv_files]2. الحصول على قيم فريدة من جدول العمود
import pandas as pd
df = pd.read_csv("path/to/csv/file.csv")
df["Item_Identifier"].unique()array(['FDA15', 'DRC01', 'FDN15', ..., 'NCF55', 'NCW30', 'NCW05'], dtype=object)3. اعرض إطارات بيانات الباندا جنبًا إلى جنب
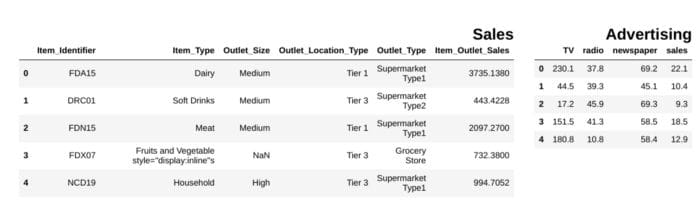
from IPython.display import display_html
from itertools import chain,cycledef display_side_by_side(*args,titles=cycle([''])): # source: https://stackoverflow.com/questions/38783027/jupyter-notebook-display-two-pandas-tables-side-by-side html_str='' for df,title in zip(args, chain(titles,cycle(['</br>'])) ): html_str+='<th style="text-align:center"><td style="vertical-align:top">' html_str+="<br>" html_str+=f'<h2>{title}</h2>' html_str+=df.to_html().replace('table','table style="display:inline"') html_str+='</td></th>' display_html(html_str,raw=True)
df1 = pd.read_csv("file.csv")
df2 = pd.read_csv("file2")
display_side_by_side(df1.head(),df2.head(), titles=['Sales','Advertising'])
### Output
الصورة من قبل المؤلف
4. إزالة جميع NaNs في إطار بيانات الباندا
df = pd.DataFrame(dict(a=[1,2,3,None]))
df
df.dropna(inplace=True)
df

5. إظهار عدد إدخالات NaN في أعمدة DataFrame
def findNaNCols(df): for col in df: print(f"Column: {col}") num_NaNs = df[col].isnull().sum() print(f"Number of NaNs: {num_NaNs}")
df = pd.DataFrame(dict(a=[1,2,3,None],b=[None,None,5,6]))
findNaNCols(df)# OutputColumn: a
Number of NaNs: 1
Column: b
Number of NaNs: 26. تحويل الأعمدة مع .apply ووظائف لامدا
df = pd.DataFrame(dict(a=[10,20,30,40,50]))
square = lambda x: x**2
df["a"]=df["a"].apply(square)
df

7. تحويل عمودين DataFrame إلى قاموس
df = pd.DataFrame(dict(a=["a","b","c"],b=[1,2,3]))
df_dictionary = dict(zip(df["a"],df["b"]))
df_dictionary{'a': 1, 'b': 2, 'c': 3}8. رسم شبكة التوزيعات مع الشروط الشرطية على الأعمدة
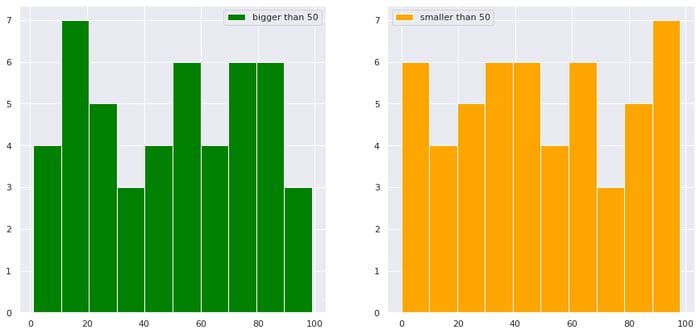
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
import pandas as pd df = pd.DataFrame(dict(a=np.random.randint(0,100,100),b=np.arange(0,100,1)))
plt.figure(figsize=(15,7))
plt.subplot(1,2,1)
df["b"][df["a"]>50].hist(color="green",label="bigger than 50")
plt.legend()
plt.subplot(1,2,2)
df["b"][df["a"]<50].hist(color="orange",label="smaller than 50")
plt.legend()
plt.show()
الصورة من قبل المؤلف
9. إجراء اختبارات t لقيم الأعمدة المختلفة في حيوانات الباندا
from scipy.stats import ttest_rel data = np.arange(0,1000,1)
data_plus_noise = np.arange(0,1000,1) + np.random.normal(0,1,1000)
df = pd.DataFrame(dict(data=data, data_plus_noise=data_plus_noise))
print(ttest_rel(df["data"],df["data_plus_noise"]))# Output
Ttest_relResult(statistic=-1.2717454718006775, pvalue=0.20375954602300195)10. دمج إطارات البيانات في عمود معين
df1 = pd.DataFrame(dict(a=[1,2,3],b=[10,20,30],col_to_merge=["a","b","c"]))
df2 = pd.DataFrame(dict(d=[10,20,100],col_to_merge=["a","b","c"]))
df_merged = df1.merge(df2, on='col_to_merge')
df_merged

11. تطبيع القيم في عمود الباندا مع sklearn
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scores = scaler.fit_transform(df["a"].values.reshape(-1,1))12. إسقاط NaNs في عمود معين في الباندا
df.dropna(subset=["col_to_remove_NaNs_from"],inplace=True)13. اختيار مجموعة فرعية من إطار البيانات مع الشرطية و or بيان
df = pd.DataFrame(dict(result=["Pass","Fail","Pass","Fail","Distinction","Distinction"]))
pass_index = (df["result"]=="Pass") | (df["result"]=="Distinction")
df_pass = df[pass_index]
df_pass

14. الرسم البياني الأساسي الدائري
import matplotlib.pyplot as plt df = pd.DataFrame(dict(a=[10,20,50,10,10],b=["A","B","C","D","E"]))
labels = df["b"]
sizes = df["a"]
plt.pie(sizes, labels=labels, autopct='%1.1f%%', shadow=True, startangle=140)
plt.axis('equal')
plt.show()

15. تغيير سلسلة النسبة المئوية إلى قيمة عددية باستخدام .apply()
def change_to_numerical(x): try: x = int(x.strip("%")[:2]) except: x = int(x.strip("%")[:1]) return x df = pd.DataFrame(dict(a=["A","B","C"],col_with_percentage=["10%","70%","20%"]))
df["col_with_percentage"] = df["col_with_percentage"].apply(change_to_numerical)
df

وفي الختام
أعتقد أن مقتطفات من التعليمات البرمجية ذات قيمة فائقة ، ويمكن أن تكون إعادة كتابة التعليمات البرمجية مضيعة حقيقية للوقت ، لذا فإن وجود مجموعة أدوات كاملة مع جميع الحلول البسيطة التي تحتاجها لتبسيط عملية تحليل البيانات الخاصة بك يمكن أن يكون مفيدًا للغاية.
إذا أعجبك هذا المنشور تواصل معي على تويتر, لينكدين: وتتبعني متوسط. شكرا ونراكم في المرة القادمة! 🙂
المزيد من المحتوى في عادي
السيرة الذاتية: لوكاس سواريس مهندس ذكاء اصطناعي يعمل على تطبيقات التعلم العميق لمجموعة واسعة من المشاكل.
أصلي. تم إعادة النشر بإذن.
هذا الموضوع ذو علاقة بـ:
| أهم الأخبار في الثلاثين يومًا الماضية | |||||
|---|---|---|---|---|---|
|
|
||||
المصدر: https://www.kdnuggets.com/2021/08/15-python-snippets-optimize-data-science-pipeline.html
- '
- "
- &
- 100
- 7
- دعاية
- AI
- الكل
- تحليل
- تطبيق
- التطبيقات
- السيارات
- AWS
- الكود
- عمود
- مشترك
- محتوى
- البيانات
- تحليل البيانات
- علم البيانات
- صفقة
- التعلم العميق
- مدير المدارس
- مهندس
- المميزات
- الاسم الأول
- اتباع
- وحدات معالجة الرسومات
- عظيم
- أخضر
- شبكة
- كيفية
- كيفية
- HTTPS
- المقابلة الشخصية
- ملصقات
- تعلم
- تعلم
- لينكدين:
- قائمة
- آلة التعلم
- متوسط
- ML
- عصبي
- جاكيت
- المصدر المفتوح
- بايثون
- نطاق
- الأسباب
- تراجع
- تشغيل
- الأملاح
- علوم
- العلماء
- مشاركة
- الاشارات
- So
- الحلول
- مربع
- الإحصائيات
- قصص
- TD
- الاختبار
- الوقت
- تيشرت
- تحويل
- قيمنا
- X